How to create useful AI applications
To create useful AI applications you need to understand how AI works and how it can best be used.
In this article we explain AI and give insights on how to create custom applications. You will see what is possible with AI out-of-the-box. You will learn what the limitations are and how to overcome them. And maybe you will get ideas on how AI applications can be used in your work.
To inspire you we will show you some engaging examples of how we have integrated LLMs in different applications at the end of this article.
What is AI?
AI stands for Artificial Intelligence, which refers to the simulation of human intelligence processes by machines, especially computer systems. Usually when we refer to AI we are actually talking about GPT applications.
GPT stands for Generative Pretrained Transformers and refers to a type that utilises a transformer architecture. This is a deep learning model architecture primarily used for natural language processing tasks.
How do Large Language Models work?
GPT models are trained on large amounts of text data and are capable of generating human-like text based on the input they receive. Due to the large amount of data these models are trained on, they are also referred to as Large Language Models or LLMs.
The "pretrained" aspect in the acronym GPT refers to the fact that these models are initially trained on a vast amount of text data using unsupervised learning techniques. During this pretraining phase, the model learns to predict the next word in a sequence of text given the preceding context. This allows the model to capture a wide range of language patterns and semantics.
The "generative" aspect in the acronym GPT signifies that these models can generate coherent and contextually relevant text based on a prompt or input provided to them. They achieve this by using the knowledge learned during pretraining to predict the most probable next word or sequence of words given the input context.
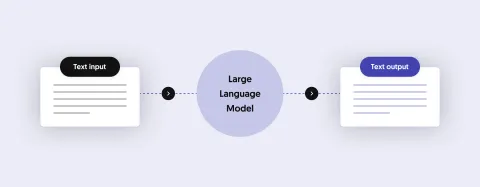
When you want to create an AI application, think of the LLM as a software that can “talk”, meaning it can create grammatically correct sentences that have a high probability of making sense.
Of course such a model can only talk about what it “knows”, meaning what it was trained on.
How are LLMs trained? Is it useful to do this myself?
Training a Large Language Model can be a challenging and resource-intensive task. It requires substantial computational resources, including powerful GPUs and a distributed training infrastructure. Training models with millions or billions of parameters is expensive and time-consuming.
Also large amounts of high-quality text data from diverse sources is needed and collecting and preprocessing such datasets typically requires significant effort to ensure data quality and diversity.
However, if sufficient infrastructure, resources, time, and data are available training is typically done using a combination of unsupervised and supervised learning techniques. As a result the intrinsic semantic and logical relationships between the elements in a dataset are discovered and are used when generating responses to data input.

However, there are a lot of pre-trained general purpose models available that can be used instead of training your own model. The most famous ones are from OpenAI and Mistral AI.
Usually, it is much more efficient to use a pre-trained model in your application in comparison to training a model with your own data.
How can I best use existing LLMs?
Large Language Models can only "talk" about topics (data) that they were trained with.
In order to answer questions about different topics this data has to be passed to the model before asking the question. This process is referred to as "in-context learning".
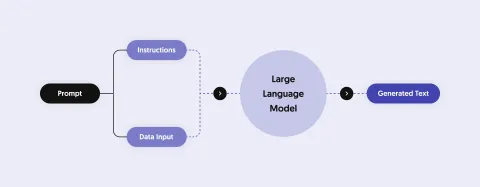
To enable your AI to talk about a specific topic you have to pass the relevant information to the model before interacting with it.
Besides passing data to a Large Language Model you typically pass instructions to a data model describing how the model should respond.
Examples of such instructions are the tonality you want to use or restricting the topics your application should respond to.
How much data can LLMs handle?
In theory, LLMs can handle unlimited data. Data passed to Large Language Models are referred to as "tokens".
There are models that exist that can handle a very large number of tokens. However, the more data you pass to the model the more the complexity increases to compute sensible responses.
Therefore, models comprehending more complex data react slower and are more expensive to operate in comparison to models that only understand simpler data.
The easier the task for the LLM is, the faster it can respond and better results can be produced.
If you pre-process the input and reduce the information in a way that only relevant data is passed to the LLM, you can create much more efficient AI applications.
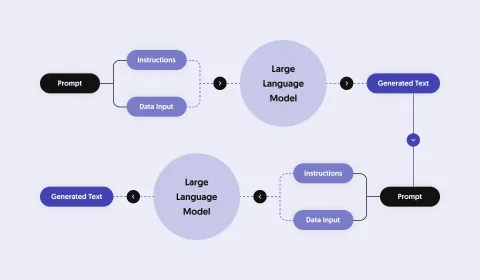
We need solid engineering for creating engaging AI applications!
In order to keep the assignments simple and fast for your applications you need to process input and output data in a smart way.
A common practice is to split an AI task into a number of subtasks that are easier to process.
This is best explained with an example. Think of an application that mimics a travel agent.
- The first task for the travel agent would be to find out where and when a person wants to travel.
- The second task would be to find (retrieve) relevant activities for the destination and the time period.
- The third task would be to consult the client to select the best out of the available activities.
The above tasks can be created as an application. Tasks one and three can be performed by an AI given the right instructions and data. Task two would be a regular data retrieval task.
This approach is often referred to as Retrieval Based Augmentation (RAG) and is a common practice to enable AI applications to operate on large datasets (for example a tourism database).
Data optimization for a multilingual AI Chatbot
One of our clients is "Insel Mainau", a famous flower island in Lake Constance in southern Germany. On their website they publish a calendar in which you can read which flowers are blooming each month on the Island.
The text is in German and if you calculate the number of tokens for the sub-pages of all 12 months you get well over 20.000 tokens. This number equals around 60.000 characters which is around 13.000 words. This is too much content for regular AI models and processing this amount of data would be too costly.
Therefore, we reduced the content by shortening it and removing all unnecessary words. With this procedure we managed to get the number of tokens for all 12 pages to less than 4.000.
Original text for month March
Was blüht im März auf der Insel Mainau?Im März freuen wir uns auf der Insel Mainau über das Comeback der Krokusse, Narzissen und Kamelien. Doch nicht nur das, denn auch die ersten Schmetterlinge haben bereits ihre Flügel entfaltet und tanzen munter durch die Lüfte.Seit 1973 ist die Orchideenschau im Palmenhaus der traditionelle Auftakt der blühenden Höhepunkte auf der Insel Mainau. Über 3.000 exotische Orchideen-Schönheiten in ihrer erstaunlichen Vielfalt an Formen und Farben werden ausgestellt. Entdecken Sie die lebendigen Farben von Phalaenopsis-, Vanda- und Cattleya-Orchideen sowie botanische Raritäten, die von unseren Gärtnern kunstvoll arrangiert werden....Reduced text for month March
MärzInsel Mainau erblüht vielfältigen Farbenspiel. Krokusse, Narzissen Kamelien bringen Frühling zurück, begleitet ersten flatternden Schmetterlingen. Traditionelle Orchideenschau Palmenhaus zeigt 3.000 exotische Orchideen faszinierenden Formen Farben. Märzenbecher kündigen weißen Blüten Ende Winters, Kamelien rosafarbenen, roten weißen Tönen Ufergarten blühen. ...
Tokens: 297
Characters: 927
As you can see from the example for the month of March above, the text was greatly reduced. Furthermore, the reduced text does not make sense for human readers any more. However, for an AI this does not matter, since it simply predicts words based on input using its trained patterns.
When passing data to a Large Language Model it is common practice to strip all unnecessary words and even send unintelligible text, because the model does not need this data to produce sensible responses.
For the demo we instructed the LLM to answer in a friendly and cheerful way to mimic the tonality of the website. Even though data is passed in German you can interact with it in both German and in English.
AI Chatbot responding in German
AI Chatbot responding in English
Try our applications on our AI demo website
You can visit our AI demo website to try the above application yourself. On the demo website you will also find more engaging AI applications that we have created. See what is possible with AI out-of-the-box!
Ready to build your own AI applications?
If you are ready to create your own application, we can help you to plan your project.
Other highlights
Why choose open source over proprietary software for enterprise projects

We often get asked what open source software is and why companies prefer it over proprietary...
Using a MVP approach for web projects
At 1xINTERNET we use a MVP (Minimum Viable Product) approach for delivering successful web projects...